선형모델
- 입력특성(데이터, 문제)을 설명할 수 있는 선형함수를 구하는 것
- 선형함수 기본식
- 문제가 1개일 때 : y= wx + b
- 문제가 p개일 때 : y = w1x1 + w2x2 + .... + wpxp + b
- w : 가중치 - 각 문제마다 다른 가중치 적용, b : 편향
- 입력 데이터를 완벽하게 설명하는 것은 불가능 ==> 오차가 가장 작은 선형함수를 찾아야함
- 오차가 가장 작은 선형함수를 찾는다는 것은? 평균제곱오차(MSE)가 가장 작은 선형함수를 찾는다.
- 평균제곱오차(MSE)가 가장 작은 선형함수 ==> 최적의 선형함수
- 평균제곱오차가 가장 작은 선형함수를 찾는 방법
-
- 수학 공식을 이용한 해석적 방법(공식으로 해결)
- 장점: 적은 계산으로 구함 --> 한번에 최적의 선형함수를 찾음
- 단점: 공식이 완벽하지 않을 경우 잘못 찾을 수도 있고 공식을 고칠 수 없는 문제
- 수학 공식을 이용한 해석적 방법(공식으로 해결)
-
- 경사하강법
- 점진적으로 오차가 작은 선형함수를 찾아가는 방법(오차를 수정)
- 장점: 잘못찾았을 때 수정 가능
- 단점: 점진적으로 찾아가므로 계산량이 많음 - 시간이 오래 걸림
- 경사하강법
-
선형회귀 이해하기
- 성적데이터를 기반으로 선형회귀를 이해해보자
In [1]:
# 성적 데이터 생성을 위한 라이브러리 꺼내오기
import pandas as pd
import matplotlib.pyplot as plt
In [2]:
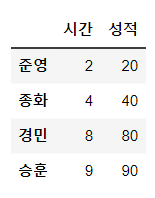
# 성적 데이터 생성
data=pd.DataFrame([[2, 20], [4, 40], [8, 80], [9, 90]],
index=['준영','종화','경민','승훈'],
columns=['시간','성적'])
data
Out[2]:
MSE가 최소가 되는 최적의 w, b를 찾는 방법
- MSE : 평균제곱오차(Mean Squared Error --> 비용함수(cost)
-
- 수학 공식을 이용한 해석적 모델
-
- 경사하강법(XGBoost에서 오차 계산하는 방법
수학 공식을 이용한 해석적 모델
- LinearRegression
- 공식을 이용해서 적은 계산으로 한번에 최적의 선형함수를 찾는 방법
- 공식이 완벽하지 않을 경우 잘 못 찾을 수도 있고
- 공식이 잘못되었을 경우 고칠 수 없다는 문제가 있음 ==> 추후 규제를 접목해서 개선할 수 있다
In [3]:
from sklearn.linear_model import LinearRegression
# 모델 생성 및 하이퍼파라미터 설정
linear_model = LinearRegression()
#학습
linear_model.fit(data[['시간']], data['성적']) # 문제는 2차원, 정답은 1차원
Out[3]:
LinearRegression
LinearRegression()y = wx + b(1개의 문제)
In [4]:
# 기울기, 가중치 출력
print('기울기, 가중치 : ', linear_model.coef_)
# 절편, 편향 출력
print('절편, 편향 : ', linear_model.intercept_)
기울기, 가중치 : [10.]
절편, 편향 : 7.105427357601002e-15
In [5]:
# 영재씨가 7시간 공부했을 때 몇 점? -예측
linear_model.predict([[7]])
C:\Users\gjaischool\anaconda3\lib\site-packages\sklearn\base.py:420: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names
warnings.warn(
Out[5]:
array([70.])
H(x)
- 가설함수
In [6]:
# 함수 정의
def h(w, x) :
return w* x + 0
비용함수(Cost Function)
- 비용 = 오차
In [7]:
# 비용함수 정의
# data : 문제 값
# target : 정답(실제 값)
# weight : 가중치
def cost(data, target, weight) :
# 예측
y_pre = h(weight, data)
# 평균제곱오차 = ((예측값 - 실제값) ** 2).mean()
error = ((y_pre - target) ** 2).mean()
return error
In [8]:
# 가중치에 따른 오차값 확인
cost(data['시간'], data['성적'], 8)
Out[8]:
165.0In [9]:
cost(data['시간'], data['성적'], 7)
Out[9]:
371.25In [10]:
cost(data['시간'], data['성적'], 10)
Out[10]:
0.0In [11]:
# 가중치 변화에 따른 비용함수의 변화를 그래프로 확인
cost_list = []
for w in range(5, 16) : # 5 ~ 15까지 가중치 변화
err = cost(data['시간'], data['성적'], w)
cost_list.append(err)
cost_list
Out[11]:
[1031.25,
660.0,
371.25,
165.0,
41.25,
0.0,
41.25,
165.0,
371.25,
660.0,
1031.25]In [12]:
# 비용함수(MSE) 그래프 그리기
plt.plot(range(5, 16), cost_list)
plt.show()
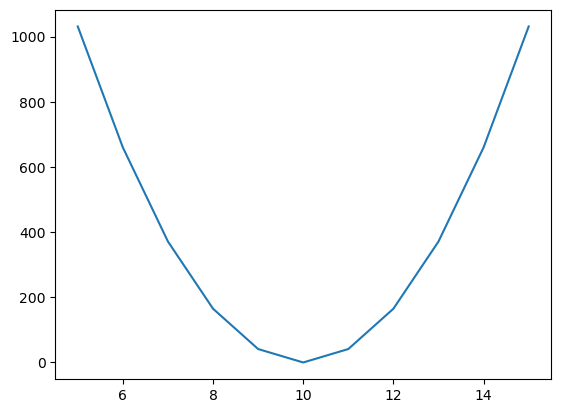
In [13]:
linear_model.score(data[['시간']], data['성적'])
# 분류모델 : score - 정확도
# 회귀모델 : score(MSE를 기반으로 한 R2score) - 유사도
Out[13]:
1.0
경사하강법
- SGDRegressor
- 점진적으로 오차가 작은 선형함수를 찾아가는 방법
- 오차를 수정하는 방향으로 그래프를 다시 그려줌
- 선형함수를 잘못 찾았을 경우 수정이 가능
- 점진적으로 찾아가므로 계산량이 많아 시간이 오래 걸림
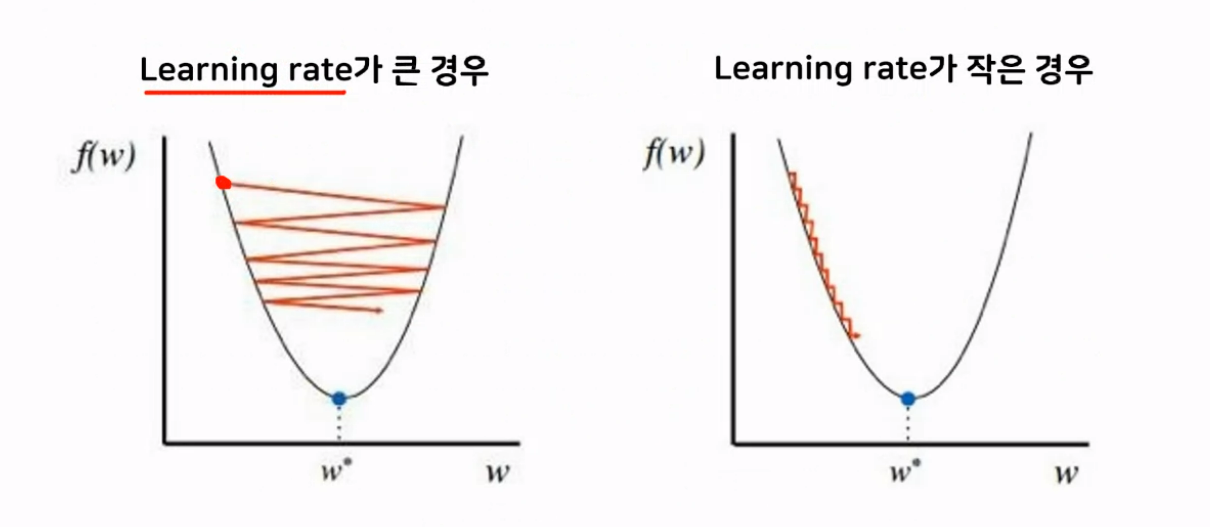
- 학습률(learning rate) : 기울기의 보폭
- 너무 크게 설정하면 오차가 커짐(발산)
- 너무 작게 설정하면 국소지역점에 빠져서 최적의 해를 찾지 못함
In [14]:
from sklearn.linear_model import SGDRegressor
# 모델생성 및 하이퍼 파라미터 설정
sgd_model = SGDRegressor(max_iter=5000, # 가중치 업데이트 반복 횟수
eta0 = 0.001, # 학습률(learning rate)
verbose = 1)
# 학습
sgd_model.fit(data[['시간']], data['성적'])
-- Epoch 1
Norm: 1.32, NNZs: 1, Bias: 0.183865, T: 4, Avg. loss: 1872.180025
Total training time: 0.00 seconds.
-- Epoch 2
Norm: 2.16, NNZs: 1, Bias: 0.303266, T: 8, Avg. loss: 1450.251703
Total training time: 0.00 seconds.
-- Epoch 3
Norm: 2.86, NNZs: 1, Bias: 0.400013, T: 12, Avg. loss: 1183.147566
Total training time: 0.00 seconds.
-- Epoch 4
Norm: 3.43, NNZs: 1, Bias: 0.480948, T: 16, Avg. loss: 983.932932
Total training time: 0.00 seconds.
-- Epoch 5
Norm: 3.94, NNZs: 1, Bias: 0.551066, T: 20, Avg. loss: 829.524367
Total training time: 0.00 seconds.
-- Epoch 6
Norm: 4.38, NNZs: 1, Bias: 0.612543, T: 24, Avg. loss: 705.709525
..............................................................
Total training time: 0.00 seconds.
-- Epoch 129
Norm: 9.79, NNZs: 1, Bias: 1.337354, T: 516, Avg. loss: 0.189823
Total training time: 0.00 seconds.
-- Epoch 130
Norm: 9.79, NNZs: 1, Bias: 1.337244, T: 520, Avg. loss: 0.189006
Total training time: 0.00 seconds.
-- Epoch 131
Norm: 9.79, NNZs: 1, Bias: 1.337128, T: 524, Avg. loss: 0.188254
Total training time: 0.00 seconds.
Convergence after 131 epochs took 0.00 secondsOut[14]:
SGDRegressor
SGDRegressor(eta0=0.001, max_iter=5000, verbose=1)In [15]:
# 예측
sgd_model.predict([[7]])
C:\Users\gjaischool\anaconda3\lib\site-packages\sklearn\base.py:420: UserWarning: X does not have valid feature names, but SGDRegressor was fitted with feature names
warnings.warn(
Out[15]:
array([69.88271009])In [16]:
# 가중치(w), 편향(b) 확인하기
print(sgd_model.coef_)
print(sgd_model.intercept_)
[9.79222597]
[1.33712829]
In [17]:
sgd_model.score(data[['시간']], data['성적'])
# 1에 가까울수록 모델이 예측한 성능이 높다고 판단
Out[17]:
0.999543523191443